RunPod GPU 가격 비교 및 가성비 분석 (2025년 최신)
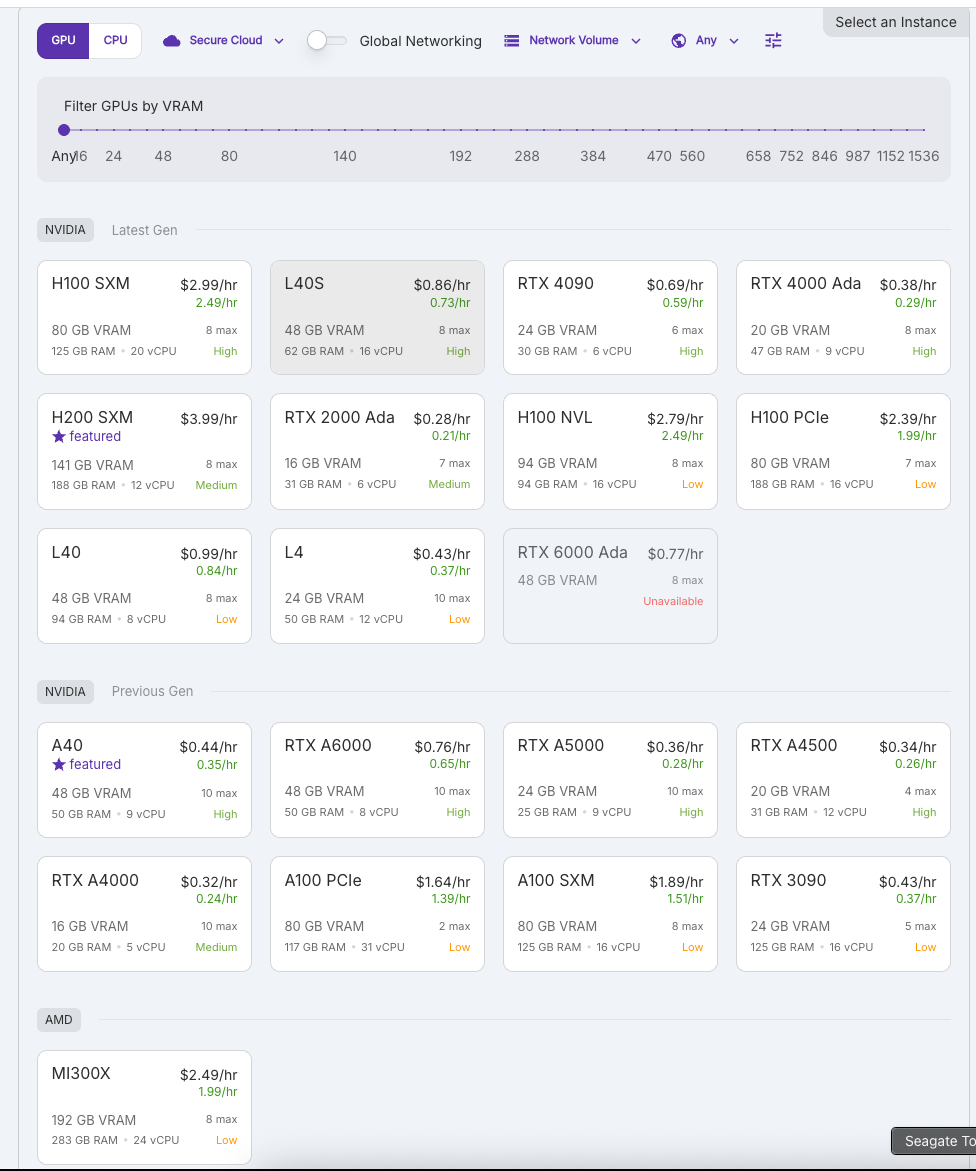
안녕하세요! 오늘은 AI 개발자와 머신러닝 연구자들이 많이 활용하는 RunPod 클라우드 GPU 서비스의 가격 비교와 가성비 분석에 대해 알아보겠습니다. 특히 VRAM 대비 가격을 중심으로 어떤 GPU가 여러분의 AI 워크로드에 가장 적합한지 살펴보겠습니다.
RunPod이란?
RunPod는 AI 개발, 머신러닝 훈련, 추론 등을 위한 GPU 클라우드 서비스로, 다양한 NVIDIA 및 AMD GPU를 온디맨드 방식으로 제공합니다. 특히 최신 GPU 모델을 경쟁력 있는 가격에 이용할 수 있어 프리랜서 개발자부터 스타트업, 연구 기관까지 널리 사용되고 있습니다.
VRAM 대비 가격 분석
AI 모델, 특히 대형 언어 모델(LLM) 및 이미지 생성 모델을 실행할 때 가장 중요한 자원은 **VRAM(비디오 메모리)**입니다. 아래는 RunPod에서 제공하는 주요 GPU의 VRAM 대비 시간당 비용을 분석한 표입니다.

주요 GPU별 상세 분석
1. NVIDIA A40 (최고의 VRAM 가성비)
- VRAM: 48GB GDDR6
- 시간당 비용: $0.35 (할인가)
- 1GB당 비용: $0.0073
- 특징:
- TensorCore 지원으로 딥러닝 성능 향상
- High 가용성으로 안정적인 작업 가능
- 9 vCPU와 50GB RAM으로 전처리 작업도 원활
A40은 VRAM 대비 가격이 가장 우수한 GPU로, 중대형 AI 모델을 다루는 데 적합합니다. 특히 LoRA 파인튜닝과 같은 메모리 집약적 작업에서 뛰어난 가성비를 보여줍니다.
2. AMD MI300X (최대 VRAM 용량)
- VRAM: 192GB HBM3
- 시간당 비용: $1.99 (할인가)
- 1GB당 비용: $0.0104
- 특징:
- 압도적인 192GB VRAM 용량
- 24 vCPU와 283GB RAM으로 강력한 성능
- 낮은 가용성(Low)이 단점
MI300X는 초대형 언어 모델(LLM) 작업에 이상적인 선택입니다. Llama-70B, Claude, GPT-4급 모델을 양자화 없이 전체 정밀도로 로드할 수 있습니다.
3. NVIDIA L40 vs L4 비교
- L40:
- 48GB VRAM, $0.84/hr, $0.0175/GB/hr
- Transformer 엔진 최적화로 어텐션 메커니즘 가속
- 8 vCPU와 94GB RAM으로 복잡한 데이터 파이프라인 지원
- L4:
- 24GB VRAM, $0.37/hr, $0.0154/GB/hr
- 저전력 설계로 추론에 최적화
- 12 vCPU와 50GB RAM으로 경량 작업에 적합
L40은 훈련 및 고급 추론에, L4는 효율적인 배포 및 서빙에 더 적합합니다.
AI 워크로드별 최적 GPU 추천
대형 언어 모델(LLM) 작업
- 전체 모델 로드: AMD MI300X (192GB) 또는 H200 SXM (141GB)
- LoRA/QLoRA 파인튜닝: A40 (48GB) 또는 L40 (48GB)
- 양자화 기반 추론: L4 (24GB) 또는 RTX A5000 (24GB)
이미지 생성 모델
- 고해상도 생성: RTX A6000 (48GB) 또는 A40 (48GB)
- 실시간 이미지 생성: RTX 4090 (24GB)
- 효율적 배치 처리: RTX 4000 Ada (20GB)
멀티모달 AI 작업
- 비전-언어 모델: L40 (48GB) 또는 A40 (48GB)
- 오디오-텍스트 변환: RTX A5000 (24GB)
- 비디오 처리: RTX 4090 (24GB) 또는 RTX A6000 (48GB)
경제적인 RunPod 사용 전략
1. 스팟 인스턴스 활용
RunPod의 스팟 인스턴스는 온디맨드 가격보다 15-40% 저렴합니다. 중단 허용 작업에는 항상 스팟 인스턴스를 활용하는 것이 경제적입니다.
2. 작업 특성에 맞는 GPU 선택
- 훈련 작업: VRAM이 큰 A40, L40, MI300X
- 추론 작업: 추론 최적화된 L4, RTX 4000 Ada
- 개발 및 실험: 비용 효율적인 RTX A4000, RTX 3090
3. 모델 최적화 기법 적용
- 양자화(Quantization): INT8/INT4 최적화로 VRAM 요구량 감소
- 모델 프루닝(Pruning): 불필요한 가중치 제거
- 모델 샤딩(Sharding): 여러 GPU에 모델 분산
VRAM과 RAM의 역할과 중요성
VRAM의 역할
- 모델 가중치 저장
- 어텐션 캐시 및 KV 캐시 관리
- 중간 활성화값 저장
- 텐서 연산 가속
시스템 RAM의 역할
- 데이터 전처리 및 배치 구성
- 모델 로딩 준비
- 결과 후처리 및 저장
- VRAM 오버플로 시 임시 저장소
대형 AI 모델을 효율적으로 실행하려면 VRAM과 RAM 간의 균형이 중요합니다. RunPod의 모든 GPU는 적절한 비율의 RAM을 제공하지만, 특별한 작업에는 더 많은 RAM이 필요할 수 있습니다.
결론: 가성비 최고의 GPU는?
VRAM 대비 가격만 고려한다면 NVIDIA A40이 명확한 승자입니다. 하지만 워크로드 특성과 실제 성능을 고려하면:
- 최고의 종합 가성비: NVIDIA A40
- 대규모 LLM 작업용: AMD MI300X
- 효율적인 추론용: NVIDIA L4
- 중소규모 프로젝트용: RTX A4000
자신의 AI 워크로드 요구사항과 예산 제약을 고려하여 최적의 GPU를 선택하는 것이 중요합니다.
마지막 팁: RunPod 사용 시 비용 절감 방법
- 사용하지 않는 인스턴스는 즉시 중지하기
- 도커 이미지 최적화로 시작 시간 단축
- 체크포인트 저장으로 작업 연속성 확보
- 볼륨 스토리지 최적화로 스토리지 비용 절감
- 자동화 스크립트로 유휴 시간 최소화
여러분은 어떤 GPU를 사용하고 계신가요? 특별한 AI 프로젝트에 적합한 GPU에 대한 조언이 필요하시면 댓글로 남겨주세요! 다음 글에서는 RunPod vs Lambda Labs vs Vast.ai 가격 비교 분석을 진행할 예정입니다. 구독과 좋아요 부탁드립니다! 👍
'개발 > Architect' 카테고리의 다른 글
| MSA(마이크로) + MA(모놀리식) :: 소프트웨어 아키텍쳐 장단점과 적용 (0) | 2022.11.11 |
|---|---|
| 크롤링과 서버 부하 관련 인사이트 (0) | 2022.10.05 |
| 현업 개발자가 생각하는 애자일의 의미 (0) | 2021.07.13 |