안녕하세요! 오늘은 AI 개발자와 머신러닝 연구자들이 많이 활용하는 RunPod 클라우드 GPU 서비스의 가격 비교와 가성비 분석에 대해 알아보겠습니다. 특히 VRAM 대비 가격을 중심으로 어떤 GPU가 여러분의 AI 워크로드에 가장 적합한지 살펴보겠습니다.
RunPod이란?
RunPod는 AI 개발, 머신러닝 훈련, 추론 등을 위한 GPU 클라우드 서비스로, 다양한 NVIDIA 및 AMD GPU를 온디맨드 방식으로 제공합니다. 특히 최신 GPU 모델을 경쟁력 있는 가격에 이용할 수 있어 프리랜서 개발자부터 스타트업, 연구 기관까지 널리 사용되고 있습니다.
VRAM 대비 가격 분석
AI 모델, 특히 대형 언어 모델(LLM) 및 이미지 생성 모델을 실행할 때 가장 중요한 자원은 **VRAM(비디오 메모리)**입니다. 아래는 RunPod에서 제공하는 주요 GPU의 VRAM 대비 시간당 비용을 분석한 표입니다.
주요 GPU별 상세 분석
1. NVIDIA A40 (최고의 VRAM 가성비)
VRAM: 48GB GDDR6
시간당 비용: $0.35 (할인가)
1GB당 비용: $0.0073
특징:
TensorCore 지원으로 딥러닝 성능 향상
High 가용성으로 안정적인 작업 가능
9 vCPU와 50GB RAM으로 전처리 작업도 원활
A40은 VRAM 대비 가격이 가장 우수한 GPU로, 중대형 AI 모델을 다루는 데 적합합니다. 특히 LoRA 파인튜닝과 같은 메모리 집약적 작업에서 뛰어난 가성비를 보여줍니다.
2. AMD MI300X (최대 VRAM 용량)
VRAM: 192GB HBM3
시간당 비용: $1.99 (할인가)
1GB당 비용: $0.0104
특징:
압도적인 192GB VRAM 용량
24 vCPU와 283GB RAM으로 강력한 성능
낮은 가용성(Low)이 단점
MI300X는 초대형 언어 모델(LLM) 작업에 이상적인 선택입니다. Llama-70B, Claude, GPT-4급 모델을 양자화 없이 전체 정밀도로 로드할 수 있습니다.
3. NVIDIA L40 vs L4 비교
L40:
48GB VRAM, $0.84/hr, $0.0175/GB/hr
Transformer 엔진 최적화로 어텐션 메커니즘 가속
8 vCPU와 94GB RAM으로 복잡한 데이터 파이프라인 지원
L4:
24GB VRAM, $0.37/hr, $0.0154/GB/hr
저전력 설계로 추론에 최적화
12 vCPU와 50GB RAM으로 경량 작업에 적합
L40은 훈련 및 고급 추론에, L4는 효율적인 배포 및 서빙에 더 적합합니다.
AI 워크로드별 최적 GPU 추천
대형 언어 모델(LLM) 작업
전체 모델 로드: AMD MI300X (192GB) 또는 H200 SXM (141GB)
LoRA/QLoRA 파인튜닝: A40 (48GB) 또는 L40 (48GB)
양자화 기반 추론: L4 (24GB) 또는 RTX A5000 (24GB)
이미지 생성 모델
고해상도 생성: RTX A6000 (48GB) 또는 A40 (48GB)
실시간 이미지 생성: RTX 4090 (24GB)
효율적 배치 처리: RTX 4000 Ada (20GB)
멀티모달 AI 작업
비전-언어 모델: L40 (48GB) 또는 A40 (48GB)
오디오-텍스트 변환: RTX A5000 (24GB)
비디오 처리: RTX 4090 (24GB) 또는 RTX A6000 (48GB)
경제적인 RunPod 사용 전략
1. 스팟 인스턴스 활용
RunPod의 스팟 인스턴스는 온디맨드 가격보다 15-40% 저렴합니다. 중단 허용 작업에는 항상 스팟 인스턴스를 활용하는 것이 경제적입니다.
2. 작업 특성에 맞는 GPU 선택
훈련 작업: VRAM이 큰 A40, L40, MI300X
추론 작업: 추론 최적화된 L4, RTX 4000 Ada
개발 및 실험: 비용 효율적인 RTX A4000, RTX 3090
3. 모델 최적화 기법 적용
양자화(Quantization): INT8/INT4 최적화로 VRAM 요구량 감소
모델 프루닝(Pruning): 불필요한 가중치 제거
모델 샤딩(Sharding): 여러 GPU에 모델 분산
VRAM과 RAM의 역할과 중요성
VRAM의 역할
모델 가중치 저장
어텐션 캐시 및 KV 캐시 관리
중간 활성화값 저장
텐서 연산 가속
시스템 RAM의 역할
데이터 전처리 및 배치 구성
모델 로딩 준비
결과 후처리 및 저장
VRAM 오버플로 시 임시 저장소
대형 AI 모델을 효율적으로 실행하려면 VRAM과 RAM 간의 균형이 중요합니다. RunPod의 모든 GPU는 적절한 비율의 RAM을 제공하지만, 특별한 작업에는 더 많은 RAM이 필요할 수 있습니다.
결론: 가성비 최고의 GPU는?
VRAM 대비 가격만 고려한다면 NVIDIA A40이 명확한 승자입니다. 하지만 워크로드 특성과 실제 성능을 고려하면:
최고의 종합 가성비: NVIDIA A40
대규모 LLM 작업용: AMD MI300X
효율적인 추론용: NVIDIA L4
중소규모 프로젝트용: RTX A4000
자신의 AI 워크로드 요구사항과 예산 제약을 고려하여 최적의 GPU를 선택하는 것이 중요합니다.
마지막 팁: RunPod 사용 시 비용 절감 방법
사용하지 않는 인스턴스는 즉시 중지하기
도커 이미지 최적화로 시작 시간 단축
체크포인트 저장으로 작업 연속성 확보
볼륨 스토리지 최적화로 스토리지 비용 절감
자동화 스크립트로 유휴 시간 최소화
여러분은 어떤 GPU를 사용하고 계신가요? 특별한 AI 프로젝트에 적합한 GPU에 대한 조언이 필요하시면 댓글로 남겨주세요! 다음 글에서는 RunPod vs Lambda Labs vs Vast.ai 가격 비교 분석을 진행할 예정입니다. 구독과 좋아요 부탁드립니다! 👍
sqlc라 최고라는 말을 듣고 적용해보았다!.. 이 도구는 SQL 스키마와 쿼리를 기반으로 타입 안전한 Go 코드를 생성해주어, 안정성과 개발 생산성을 높여준다고 합니다. 이번 글에서는 sqlc를 사용하여 PostgreSQL 데이터베이스와 상호작용하는 방법에 대해 살펴보겠습니다.
2. sqlc 설정
sqlc를 사용하기 위해서는 먼저 sqlc.yaml 설정 파일을 생성해야 합니다. 이 파일에는 데이터베이스 엔진, 쿼리 파일, 스키마 파일, 그리고 생성된 Go 코드의 출력 위치 등을 지정합니다.
schema.sql 파일에 데이터베이스 테이블 구조를 정의합니다. 예를 들어, authors 테이블을 다음과 같이 정의할 수 있습니다
CREATE TABLE authors (
id BIGSERIAL PRIMARY KEY,
name text NOT NULL,
bio text
);
테이블 정보를 담은 DDL을 실행해 줍니다. 자동으로 마이그레이션을 해주고, 마이그레이션 파일을 저장해주는 라이브러리가 있다고 하는데, 다음에 적용해볼 예정입니다.
4. 쿼리 작성
query.sql 파일에 필요한 데이터베이스 쿼리를 작성합니다. sqlc는 이 쿼리들을 분석하여 Go 함수로 변환합니다.
-- name: GetAuthor :one
SELECT * FROM authors
WHERE id = $1 LIMIT 1;
-- name: ListAuthors :many
SELECT * FROM authors
ORDER BY name;
-- name: CreateAuthor :one
INSERT INTO authors (
name, bio
) VALUES (
$1, $2
)
RETURNING *;
-- name: UpdateAuthor :exec
UPDATE authors
set name = $2,
bio = $3
WHERE id = $1;
-- name: DeleteAuthor :exec
DELETE FROM authors
WHERE id = $1;
5. 코드 생성
sqlc 설정이 완료되면, 다음 명령어를 실행하여 Go 코드를 생성합니다
sqlc generate
이 명령은 db/ 폴더 내에 query.sql.go, models.go, db.go 파일을 생성합니다. 이 파일들에는 데이터베이스 SQL 구문을 실행하기 위한 함수들이 포함되어 있습니다.
6. 생성된 코드 사용
생성된 코드를 사용하여 데이터베이스 작업을 수행할 수 있습니다. 예를 들어
// Code generated by sqlc. DO NOT EDIT.
// versions:
// sqlc v1.26.0
// source: query.sql
package db
import (
"context"
"github.com/jackc/pgx/v5/pgtype"
)
const createAuthor = `-- name: CreateAuthor :one
INSERT INTO authors (
name, bio
) VALUES (
$1, $2
)
RETURNING id, name, bio
`
type CreateAuthorParams struct {
Name string
Bio pgtype.Text
}
func (q *Queries) CreateAuthor(ctx context.Context, arg CreateAuthorParams) (Author, error) {
row := q.db.QueryRow(ctx, createAuthor, arg.Name, arg.Bio)
var i Author
err := row.Scan(&i.ID, &i.Name, &i.Bio)
return i, err
}
const deleteAuthor = `-- name: DeleteAuthor :exec
DELETE FROM authors
WHERE id = $1
`
func (q *Queries) DeleteAuthor(ctx context.Context, id int64) error {
_, err := q.db.Exec(ctx, deleteAuthor, id)
return err
}
const getAuthor = `-- name: GetAuthor :one
SELECT id, name, bio FROM authors
WHERE id = $1 LIMIT 1
`
func (q *Queries) GetAuthor(ctx context.Context, id int64) (Author, error) {
row := q.db.QueryRow(ctx, getAuthor, id)
var i Author
err := row.Scan(&i.ID, &i.Name, &i.Bio)
return i, err
}
const listAuthors = `-- name: ListAuthors :many
SELECT id, name, bio FROM authors
ORDER BY name
`
func (q *Queries) ListAuthors(ctx context.Context) ([]Author, error) {
rows, err := q.db.Query(ctx, listAuthors)
if err != nil {
return nil, err
}
defer rows.Close()
var items []Author
for rows.Next() {
var i Author
if err := rows.Scan(&i.ID, &i.Name, &i.Bio); err != nil {
return nil, err
}
items = append(items, i)
}
if err := rows.Err(); err != nil {
return nil, err
}
return items, nil
}
const updateAuthor = `-- name: UpdateAuthor :exec
UPDATE authors
set name = $2,
bio = $3
WHERE id = $1
`
type UpdateAuthorParams struct {
ID int64
Name string
Bio pgtype.Text
}
func (q *Queries) UpdateAuthor(ctx context.Context, arg UpdateAuthorParams) error {
_, err := q.db.Exec(ctx, updateAuthor, arg.ID, arg.Name, arg.Bio)
return err
}
import (
"context"
"your-project/db"
)
func main() {
// 데이터베이스 연결 설정
conn, err := pgx.Connect(context.Background(), "your-database-url")
if err != nil {
log.Fatal(err)
}
defer conn.Close(context.Background())
queries := db.New(conn)
// 새 저자 생성
author, err := queries.CreateAuthor(context.Background(), db.CreateAuthorParams{
Name: "John Doe",
Bio: pgtype.Text{String: "A prolific writer", Valid: true},
})
if err != nil {
log.Fatal(err)
}
fmt.Printf("Created author: %v\n", author)
// 저자 목록 조회
authors, err := queries.ListAuthors(context.Background())
if err != nil {
log.Fatal(err)
}
for _, a := range authors {
fmt.Printf("Author: %s\n", a.Name)
}
}
sqlc를 사용하면 데이터베이스 스키마, SQL 쿼리와 Go 코드 사이의 불일치를 줄이고, type-safe을 보장하며, 개발 생산성을 향상시킬 수 있습니다. 또한 데이터베이스 스키마 변경 시 자동으로 코드를 업데이트할 수 있어 유지보수가 용이하다고 합니다.
결론적으로, sqlc는 Go와 PostgreSQL을 함께 사용하는 프로젝트에서 강력한 도구가 될 수 있습니다. 타입 안전한 데이터베이스 액세스 코드를 자동으로 생성함으로써 개발자는 비즈니스 로직에 더 집중할 수 있게 되며, 데이터베이스 관련 오류를 크게 줄일 수 있는 장점이 있다고 합니다.
생성형 AI로 일적으로나 생활적으로 도움을 많이 받고 있는 요즘, 업무 차원에서 개발 속도를 어떻게 하면 더욱 향상시킬까 하는 고민이 많은데요.
하지만 때로는 우리가 선택한 개발 및 배포 환경이 개발 속도를 방해하곤 합니다. 저 역시 최근에 그런 경험을 했습니다.
1. 기존 배포 방식의 단점
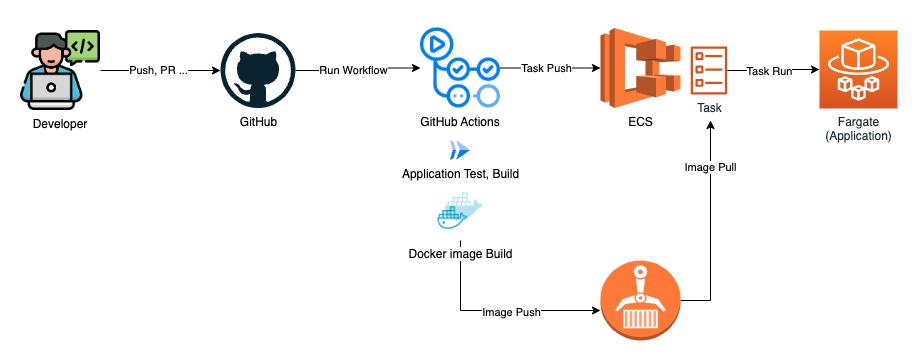
이전에 저는 docker + GitHub Actions + ECS + ECR 조합으로 배포 파이프라인을 구축했습니다. 이 방식은 코드를 푸시하는 순간 자동으로 배포가 이루어지고 github에서 종합적으로 관리할 수 있다는 장점이 있었죠. 하지만 실제로 develop 브랜치에 푸시되고 github action으로 docker 이미지가 빌드되고, ECS의 Task가 생성될 때까지, 즉, 서버에 변경사항이 반영되기까지 무려 5분이나 걸렸습니다.
처음에는 '자동화됐으니 괜찮아'라고 생각했지만, 점점 이 긴 대기 시간(코드를 변경하고 서버에 반영되는 시간)이 답답하게 느껴졌습니다. 특히 릴리즈 환경이 아니라 소규모로 개발하는 경우에는 이 5분의 대기 시간이 개발 속도에 상당한 영향을 미쳤습니다. 작은 변경사항 하나 를 커밋하고 테스트하려고 해도 커피 한 잔 마시고 올 시간이 있었으니까요.
물론 여러 명이 협업할 때는 이런 자동화된 파이프라인이 분명한 장점이 있습니다. 하지만 개인 프로젝트나 빠른 개발이 필요한 상황에서는 오히려 족쇄가 되는 느낌이었습니다.
2. 새로운 배포 방식: ssh config와 shell script의 활용
이러한 문제를 해결하기 위해 저는 좀 더 단순하면서도 빠른 배포 방식을 고안했습니다. 바로 ssh config와 shell script를 활용한 방법입니다.
새로운 방식의 흐름은 다음과 같습니다:
1. 로컬 환경에서 Docker 이미지를 빌드합니다. (I love M2 Pro 맥북❤️)
2. 빌드된 이미지를 Docker hub에 푸시합니다.
3. ssh를 통해 AWS EC2 서버에 원격으로 접속합니다.
4. 서버에서 최신 Docker 이미지를 풀(pull)받습니다.
5. 풀받은 이미지로 컨테이너를 실행합니다.
이 모든 과정을 shell script로 자동화했더니, 놀랍게도 전체 배포 시간이 28초 정도로 줄어들었습니다! 기존 방식의 약 5분(300초)에서 1/10 수준으로 단축된 것이죠.
28초 ㅁㅊㄷ..!
3. 결론
개발 환경과 배포 방식은 항상 트레이드오프가 있습니다. 팀 규모, 프로젝트의 성격, 개발 단계 등에 따라 최적의 방식이 달라질 수 있습니다. 이번 경험을 통해 저는 상황에 맞는 유연한 접근이 중요하다는 것을 깨달았습니다. 때로는 '최신' 기술 스택보다 단순하지만 효율적인 방식이 더 나을 수 있다는 것도 알게 되었고요.
여러분도 현재 사용 중인 개발 및 배포 프로세스를 한 번 점검해보는 것은 어떨까요? 어쩌면 작은 변화로 큰 효율을 얻을 수 있을지도 모릅니다.
인프라에 대해 공부해보다가 Go + Docker + ECS + Fargate + ECR + Github Action으로 CI/CD를 구성했다는 블로그 글을 보고, 따라해 보았다.
2. Dockerfile 만들기
Dockerfile은 Docker 이미지를 생성하기 위한 설정 파일입니다. Go + gin backend를 위한 Dockerfile을 만들어 보겠습니다.
FROM golang:alpine AS builder
ENV GO111MODULE=on \
CGO_ENABLED=0 \
GOOS=linux \
GOARCH=amd64
WORKDIR /build
COPY go.mod go.sum main.go ./
RUN go mod download
RUN go build -o main .
WORKDIR /dist
RUN cp /build/main .
FROM scratch
COPY --from=builder /dist/main .
ENTRYPOINT ["/main"]
3. ECS 만들기 (Fargate vs EC2)
Amazon ECS(Elastic Container Service)는 컨테이너화된 애플리케이션을 쉽게 실행하고 관리할 수 있는 완전 관리형 컨테이너 오케스트레이션 서비스입니다. ECS를 사용할 때 두 가지 주요 실행 모드가 있습니다 (Fargate, EC2). 생성할 때 두 개 중 하나를 선택할 수 있습니다. 저는 Fargate를 선택했습니다.
Fargate
서버리스 옵션으로, 인프라 관리 없이 컨테이너를 실행할 수 있습니다. 확장성이 뛰어나고 관리가 쉽습니다.
EC2
사용자가 직접 EC2 인스턴스를 관리하며, 더 많은 제어와 커스터마이징이 가능합니다.
예전에는 EC2 + Code Deploy 조합으로 배포 인프라 구성을 하곤 했는데, 이번에는 Fargate를 시도해보고자 합니다.
Fargate는 인프라 관리 부담을 줄이고 싶은 경우에 적합하며, EC2는 더 세밀한 제어가 필요한 경우에 선택한다고 합니다.
클러스터 (Cluster) 개념
ECS의 최상위 리소스 그룹입니다. 여러 개의 EC2 인스턴스 또는 Fargate 작업을 논리적으로 그룹화합니다. (저는 Fargate를 사용했습니다.) 한 클러스터 내에서 여러 서비스와 태스크를 실행할 수 있습니다.
태스크 (Task) 개념
애플리케이션의 최소 배포 단위입니다. 하나 이상의 컨테이너로 구성됩니다. 태스크 정의(Task Definition)를 통해 실행할 컨테이너, 사용할 리소스 등을 정의합니다.
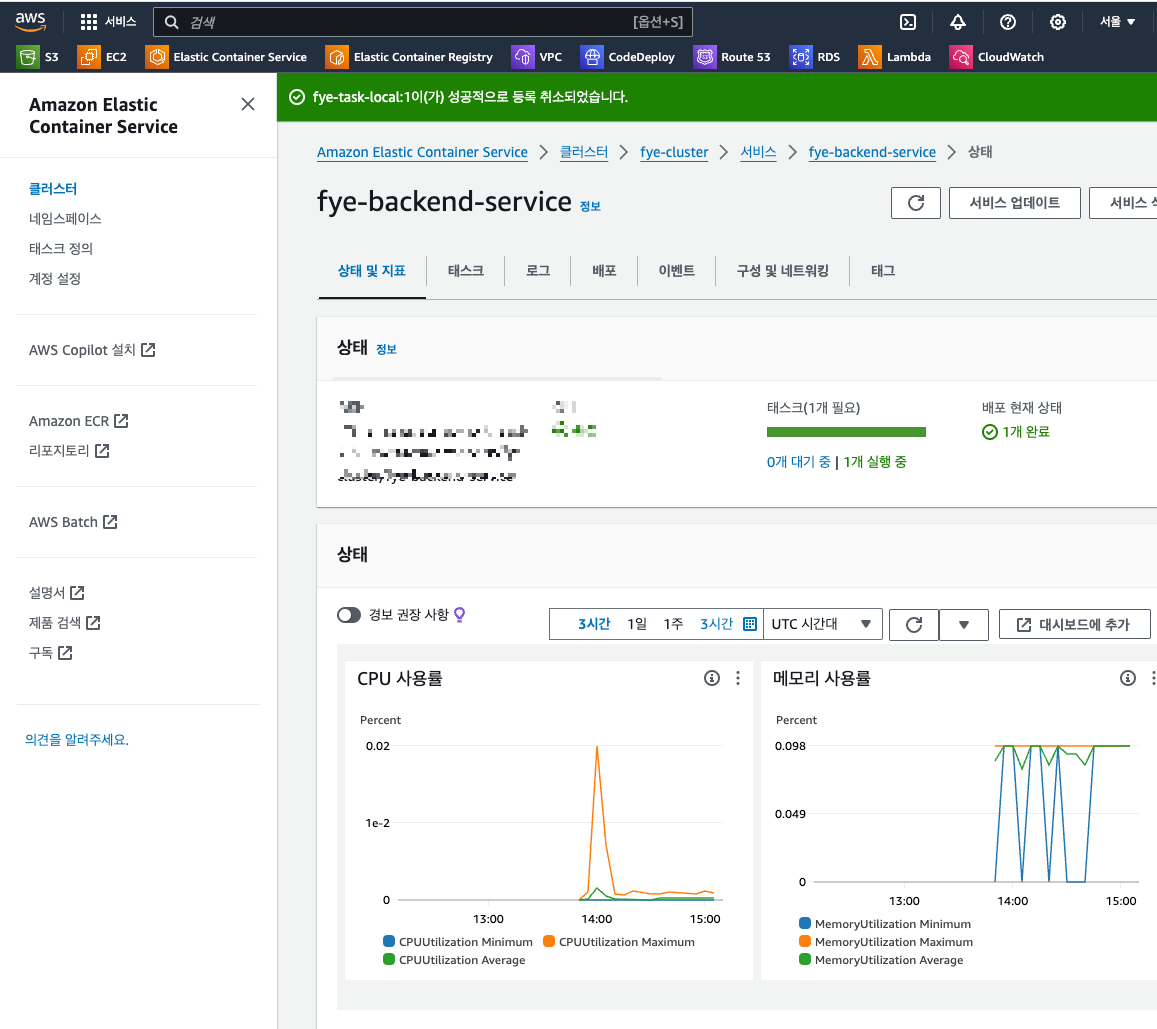
서비스 (Service)
지정된 수의 태스크를 클러스터에서 동시에 실행하고 관리합니다. 태스크가 중지되면 자동으로 새 태스크를 시작하여 지정된 개수를 유지합니다. (저는 1개를 지정해서 최대 1개만 실행됩니다.) 로드 밸런서와 연결하여 트래픽을 분산할 수 있다고 합니다. (요금 주의)
컨테이너 (Container)
Docker 이미지를 기반으로 실행되는 격리된 실행 환경입니다. (ECR에 push하고 태그로 관리됩니다) go + gin 으로 구성된 프로젝트를 Docker로 빌드했습니다. 태스크 내에서 하나 이상의 컨테이너가 함께 실행될 수 있습니다.
4. 인바운드 규칙 편집
8080 포트 열기 (인바운드 규칙 편집)
ECS 태스크가 실행되는 Fargate 태스크에 연결된 보안 그룹의 인바운드 규칙을 편집해야 합니다. ECS -> 클러스터 -> 서비스 -> 보안 그룹으로 이동합니다. 해당 보안 그룹을 선택하고 "인바운드 규칙 편집"을 클릭합니다.
유형: 사용자 지정 TCP 포트 범위: 8080 소스: 필요에 따라 특정 IP 범위 또는 모든 트래픽(0.0.0.0/0)을 선택
저는 8080포트를 열었으므로, 8080포트를 외부에서 접근 가능하도록 개방했습니다.
이렇게 설정하면 외부에서 8080 포트를 통해 ECS에서 실행 중인 go backend app에 접근할 수 있게 됩니다. 단, 보안을 위해 가능한 한 접근을 제한적으로 설정하는 것이 좋습니다. 또한, 태스크 정의에서도 컨테이너 포트 매핑을 설정해야 합니다. 태스크 정의의 컨테이너 설정에서 8080 포트를 호스트 포트와 매핑해야 합니다.
4. ECR 만들기 (Docker 이미지 저장소)
Amazon ECR(Elastic Container Registry)은 Docker 컨테이너 이미지를 안전하게 저장, 관리 및 배포할 수 있는 완전 관리형 Docker 컨테이너 레지스트리입니다. ECR을 사용하면 프라이빗 레포지토리를 생성하여 Docker 이미지를 저장하고, ECS와 쉽게 통합할 수 있습니다.
5. Github Action (develop branch에 머지 시 워크플로우 실행)
develop 브랜치에 머지가 되었을 때 (이벤트 발생), Docker 이미지가 빌드되고 ECR에 push(업로드)된 다음에, 해당 도커 이미지를 ECS에서 실행되게 할 것입니다. (8080포트로 접근 가능하게)
GitHub Actions를 사용하면 이러한 CI/CD 파이프라인을 구축할 수 있습니다. develop 브랜치에 머지될 때 자동으로 빌드, 테스트, 배포 과정을 실행하도록 설정할 수 있습니다.
aws.yml 코드
name: Deploy to Amazon ECS
on:
push:
branches: [ "develop" ]
env:
AWS_REGION: ap-northeast-2 # set this to your preferred AWS region, e.g. us-west-1
ECR_REPOSITORY: fye-backend-repository # set this to your Amazon ECR repository name
ECS_SERVICE: fye-backend-service # set this to your Amazon ECS service name
ECS_CLUSTER: fye-cluster # set this to your Amazon ECS cluster name
ECS_TASK_DEFINITION: ./fye-task.json # set this to the path to your Amazon ECS task definition
# file, e.g. .aws/task-definition.json
CONTAINER_NAME: fye-backend-container # set this to the name of the container in the
# containerDefinitions section of your task definition
permissions:
contents: read
jobs:
deploy:
name: Deploy
runs-on: ubuntu-latest
environment: production
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ env.AWS_REGION }}
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
- name: Build, tag, and push image to Amazon ECR
id: build-image
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
IMAGE_TAG: ${{ github.sha }}
run: |
# Build a docker container and
# push it to ECR so that it can
# be deployed to ECS.
docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG .
docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
echo "image=$ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG" >> $GITHUB_OUTPUT
- name: Fill in the new image ID in the Amazon ECS task definition
id: task-def
uses: aws-actions/amazon-ecs-render-task-definition@v1
with:
task-definition: ${{ env.ECS_TASK_DEFINITION }}
container-name: ${{ env.CONTAINER_NAME }}
image: ${{ steps.build-image.outputs.image }}
- name: Deploy Amazon ECS task definition
uses: aws-actions/amazon-ecs-deploy-task-definition@v1
with:
task-definition: ${{ steps.task-def.outputs.task-definition }}
service: ${{ env.ECS_SERVICE }}
cluster: ${{ env.ECS_CLUSTER }}
wait-for-service-stability: true
상단에 있는 env: 부분에서 지역과 ecs, ecr 관련 정보들을 넣습니다. json은 태스크 탭에서 다운로드할 수 있습니다. 그리고 iam을 생성해서 github secrets에 access key와 secret key를 등록하여 github action이 aws의 다양한 서비스를 조작할 수 있게 설정합니다. 저는 iam에 아래의 6개 권한을 추가했습니다. 그리고 .csv로 추출하여 github의 secret에 키를 등록했습니다.
6개 권한 추가인프라 구성 성공!, 수많은 시도들..
6. 마무리 및 소감
No Docker + Code Deploy로 했을 때는 1~2분이면 서버 배포가 끝났는데, Docker + ECS로 해보니 생각보다 오래 걸려서 당황했다..
Docker Build 하는데만 48s, Deploy ECS Task Definition 하는 데만 4m 16s가 걸렸다. 총 5분..
다수가 협업할 때는 장점이 충분히 있을 것 같지만, 1인이나 소규모로 할 때는 No Docker + Code Deploy를 사용하는 게 속도면에서 좋을 것 같다.
Golang으로 대량 API 요청 처리: Excel 파일에서 데이터 읽기부터 병렬 처리까지
안녕하세요, 오늘은 Go 언어를 사용하여 Excel 파일에서 데이터를 읽어와 대량의 API 요청을 처리하는 방법에 대해 알아보겠습니다. 이 프로그램은 입력할 Excel 파일에서 데이터를 읽어와 body에 넣어서 API에 요청을 보내고, 응답을 파일에 저장하는 과정을 수행합니다.
1. 과정
Excel 파일에서 데이터 추출하기 (API request body에 넣을 값들)
API 요청 (병렬 처리를 위한 고루틴 사용 - WaitGroup)
응답 데이터 정렬 by index
결과를 파일로 저장 (csv)
로깅 (응답 데이터, 응답 시간 로그 파일 생성)
2. Excel 파일에서 원하는 데이터 추출하기
먼저, Excel 파일에서 데이터를 읽어오는 코드를 만듭니다.
package main
import (
"encoding/csv"
"fmt"
"io/ioutil"
"log"
"os"
"strings"
"time"
"github.com/tealeg/xlsx"
)
const (
FILE_PATH = "./sample.xlsx"
SHEET_INDEX = 1
COLUMN = 'F'
START_ROW = 2
END_ROW = 186
PREVIEW_LENGTH = 500
)
func currentDateString() string {
return time.Now().Format("20060102")
}
func readExcelColumn(filePath string, column rune, startRow, endRow int) ([]string, error) {
xlFile, err := xlsx.OpenFile(filePath)
if err != nil {
return nil, fmt.Errorf("error: file '%s' not found", filePath)
}
if SHEET_INDEX >= len(xlFile.Sheets) {
return nil, fmt.Errorf("error: sheet index out of range")
}
sheet := xlFile.Sheets[SHEET_INDEX]
columnIndex := int(column - 'A')
var columnData []string
for i := startRow - 1; i < endRow; i++ {
if i >= len(sheet.Rows) {
break
}
cell := sheet.Rows[i].Cells[columnIndex]
columnData = append(columnData, cell.String())
}
return columnData, nil
}
func processCellData(cellData string) string {
parts := strings.Split(cellData, "\n")
if len(parts) > 1 {
return strings.TrimSpace(parts[1])
}
return strings.TrimSpace(parts[0])
}
func processColumnData(columnData []string) []string {
var processedData []string
for _, cell := range columnData {
processedData = append(processedData, processCellData(cell))
}
return processedData
}
func saveToCSV(data []string, outputFile string) error {
file, err := os.Create(outputFile)
if err != nil {
return fmt.Errorf("error writing to file: %v", err)
}
defer file.Close()
writer := csv.NewWriter(file)
defer writer.Flush()
for _, item := range data {
if err := writer.Write([]string{item}); err != nil {
return fmt.Errorf("error writing to file: %v", err)
}
}
fmt.Printf("Data has been saved to %s\n", outputFile)
return nil
}
func previewFile(filePath string, length int) error {
data, err := ioutil.ReadFile(filePath)
if err != nil {
return fmt.Errorf("error reading file for preview: %v", err)
}
fmt.Println("Preview of saved data:")
fmt.Println(string(data)[:length])
return nil
}
func main() {
currentDate := currentDateString()
outputFile := fmt.Sprintf("./body_%s.csv", currentDate)
columnData, err := readExcelColumn(FILE_PATH, COLUMN, START_ROW, END_ROW)
if err != nil {
log.Fatalf("Failed to read Excel column: %v", err)
}
if len(columnData) == 0 {
log.Println("No data to process. Check the Excel file and column specification.")
return
}
processedData := processColumnData(columnData)
if err := saveToCSV(processedData, outputFile); err != nil {
log.Fatalf("Failed to save to CSV: %v", err)
}
if err := previewFile(outputFile, PREVIEW_LENGTH); err != nil {
log.Fatalf("Failed to preview file: %v", err)
}
}
3. 읽어온 데이터를 바탕으로 다수의 API 요청 보내기
WaitGroup을 사용해서 동시성을 활용해 API를 병렬적으로 실행합니다.
동시 작업 추적
WaitGroup은 완료되어야 할 고루틴(goroutine)의 수를 추적합니다. 이는 여러 고루틴이 병렬로 실행될 때 유용합니다.
작업 완료 대기
Main Go routine 이 모든 작업이 완료될 때까지 기다릴 수 있게 해줍니다. 이를 통해 모든 병렬 작업이 끝날 때까지 프로그램이 종료되지 않도록 합니다.
카운터 메커니즘
WaitGroup은 내부적으로 카운터를 사용합니다. 이 카운터는 다음 메서드들로 조작됩니다:
- Add(delta int): 대기해야 할 고루틴의 수를 증가시킵니다. - Done(): 고루틴 하나가 완료되었음을 알립니다 (내부적으로 Add(-1)과 동일). - Wait(): 카운터가 0이 될 때까지 블록합니다.
그리고 1번 요청을 먼저 했다고 해도 30번째 요청의 응답이 먼저 들어올 수 있으므로 index를 지정해서 모든 요청이 완료된 순간, index를 기준으로 오름차순 정렬을 하게 했습니다.
이로써, 동시성 프로그래밍을 활용하여 30개의 API 요청 시 응답시간을 270s -> 9s로 (1개 요청 시 보통 9s) 시간을 단축하였습니다.
package main
import (
"bytes"
"encoding/csv"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
"os"
"sort"
"strconv"
"sync"
"time"
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
)
// 상수 정의
const (
INPUT_FILE = "body_20240714.csv" // 입력 CSV 파일 이름
API_URL = "http://localhost:8000/api/v1/xxxx" // API URL
ASSISTANT_CONTENT = "" //
DATE_FORMAT = "20240712" // 날짜 형식
OUTPUT_CSV_FILE = "response_20240712.csv" // 출력 CSV 파일 이름
)
// CSV 파일 읽기 함수
func readCSV(filename string, logger *zap.Logger) ([]string, error) {
logger.Info("Reading CSV file", zap.String("filename", filename)) // CSV 파일 읽기 시작 로그
file, err := os.Open(filename)
if err != nil {
return nil, fmt.Errorf("Error opening file: %w", err) // 파일 열기 오류 시 에러 반환
}
defer file.Close()
reader := csv.NewReader(file)
var data []string
for {
record, err := reader.Read()
if err != nil {
break // 더 이상 읽을 레코드가 없으면 종료
}
if len(record) > 0 {
data = append(data, record[0]) // CSV 레코드의 첫 번째 필드만 저장
}
}
logger.Info("Successfully read records from CSV file", zap.Int("records", len(data))) // 성공적으로 읽은 레코드 수 로그
return data, nil
}
// API 요청 함수
func makeAPIRequest(userContent string, wg *sync.WaitGroup, results chan<- [2]string, index int, logger *zap.Logger) {
defer wg.Done() // 작업이 완료되면 WaitGroup의 작업 카운터를 줄임
logger.Info("Making API request", zap.Int("index", index), zap.String("userContent", userContent)) // API 요청 시작 로그
startTime := time.Now() // 요청 시작 시간 기록
requestData := []map[string]string{
// 원하는 데이터 요청 형식
}
jsonData, err := json.Marshal(requestData)
if err != nil {
results <- [2]string{fmt.Sprintf("Error marshalling JSON: %v", err), fmt.Sprintf("%d", index)}
logger.Error("Error marshalling JSON", zap.Int("index", index), zap.Error(err)) // JSON 변환 오류 로그
return
}
req, err := http.NewRequest("POST", API_URL, bytes.NewBuffer(jsonData))
if err != nil {
results <- [2]string{fmt.Sprintf("Error creating request: %v", err), fmt.Sprintf("%d", index)}
logger.Error("Error creating request", zap.Int("index", index), zap.Error(err)) // HTTP 요청 생성 오류 로그
return
}
req.Header.Set("Content-Type", "application/json") // 요청 헤더 설정
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
results <- [2]string{fmt.Sprintf("Error making API request: %v", err), fmt.Sprintf("%d", index)}
logger.Error("Error making API request", zap.Int("index", index), zap.Error(err)) // API 요청 오류 로그
return
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
results <- [2]string{fmt.Sprintf("Error reading response: %v", err), fmt.Sprintf("%d", index)}
logger.Error("Error reading response", zap.Int("index", index), zap.Error(err)) // 응답 읽기 오류 로그
return
}
var response map[string]interface{}
if err := json.Unmarshal(body, &response); err != nil {
results <- [2]string{fmt.Sprintf("Invalid response format: %s", string(body)), fmt.Sprintf("%d", index)}
logger.Error("Invalid response format", zap.Int("index", index), zap.String("body", string(body))) // 응답 형식 오류 로그
return
}
if output, ok := response["output"].(string); ok {
results <- [2]string{output, fmt.Sprintf("%d", index)}
duration := time.Since(startTime) // 요청 소요 시간 계산
logger.Info("Received valid response", zap.Int("index", index), zap.String("response", output), zap.Duration("duration", duration)) // 유효한 응답 로그 및 소요 시간 기록
} else {
results <- [2]string{"No output field in response", fmt.Sprintf("%d", index)}
logger.Warn("No output field in response", zap.Int("index", index)) // 응답에 output 필드가 없음 로그
}
}
// CSV 파일에 데이터 저장 함수
func saveToCSV(filename string, data [][2]string, logger *zap.Logger) error {
logger.Info("Saving data to CSV file", zap.String("filename", filename)) // CSV 파일 저장 시작 로그
file, err := os.Create(filename)
if err != nil {
return fmt.Errorf("Error creating CSV file: %w", err) // 파일 생성 오류 시 에러 반환
}
defer file.Close()
writer := csv.NewWriter(file)
defer writer.Flush()
for _, value := range data {
if err := writer.Write([]string{value[0]}); err != nil {
return fmt.Errorf("Error writing record to CSV file: %w", err) // 레코드 작성 오류 시 에러 반환
}
}
logger.Info("Successfully saved data to CSV file") // 데이터 저장 성공 로그
return nil
}
func fileLogger(filename string) *zap.Logger {
config := zap.NewProductionEncoderConfig()
config.EncodeLevel = zapcore.CapitalColorLevelEncoder
config.EncodeTime = zapcore.ISO8601TimeEncoder
fileEncoder := zapcore.NewJSONEncoder(config)
consoleEncoder := zapcore.NewConsoleEncoder(config)
logFile, _ := os.OpenFile(filename, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
writer := zapcore.AddSync(logFile)
defaultLogLevel := zapcore.DebugLevel
core := zapcore.NewTee(
zapcore.NewCore(fileEncoder, writer, defaultLogLevel),
zapcore.NewCore(consoleEncoder, zapcore.AddSync(os.Stdout), defaultLogLevel),
)
logger := zap.New(core, zap.AddCaller(), zap.AddStacktrace(zapcore.ErrorLevel))
return logger
}
func main() {
filename := "logs.log"
logger := fileLogger(filename)
defer logger.Sync()
var startIndex, endIndex int
var err error
// 터미널에서 시작 인덱스와 끝 인덱스를 입력받음
fmt.Print("startIndex(0~184): ") // 0 -> 2
_, err = fmt.Scan(&startIndex)
if err != nil {
logger.Fatal("Error reading start index", zap.Error(err)) // 시작 인덱스 읽기 오류 시 프로그램 종료
}
fmt.Print("endIndex(1~185): ")
_, err = fmt.Scan(&endIndex)
if err != nil {
logger.Fatal("Error reading end index", zap.Error(err)) // 끝 인덱스 읽기 오류 시 프로그램 종료
}
// CSV 파일에서 질문 읽기
questions, err := readCSV(INPUT_FILE, logger)
if err != nil {
logger.Fatal("Error reading CSV file", zap.Error(err)) // CSV 파일 읽기 오류 시 프로그램 종료
}
// 끝 인덱스가 0이거나 질문 수보다 큰 경우 질문 수로 설정
if endIndex == 0 || endIndex > len(questions) {
endIndex = len(questions)
}
var wg sync.WaitGroup
results := make(chan [2]string, endIndex-startIndex)
// 시작 인덱스부터 끝 인덱스까지 API 요청 생성
for i := startIndex; i < endIndex; i++ {
wg.Add(1) // WaitGroup 카운터 증가
go makeAPIRequest(questions[i], &wg, results, i, logger) // 고루틴으로 API 요청 실행
}
wg.Wait() // 모든 고루틴이 완료될 때까지 대기
close(results) // 채널 닫기
var responseData [][2]string
for response := range results {
responseData = append(responseData, response) // 응답 데이터 수집
}
// 응답 데이터를 index 기준으로 오름차순 정렬
sort.Slice(responseData, func(i, j int) bool {
indexI, _ := strconv.Atoi(responseData[i][1])
indexJ, _ := strconv.Atoi(responseData[j][1])
return indexI < indexJ
})
// 정렬된 데이터의 텍스트 내용만 CSV 파일에 저장
var sortedTextData [][2]string
for _, value := range responseData {
sortedTextData = append(sortedTextData, [2]string{value[0]})
}
// 응답 데이터를 CSV 파일에 저장
if err := saveToCSV(OUTPUT_CSV_FILE, sortedTextData, logger); err != nil {
logger.Fatal("Error saving to CSV", zap.Error(err)) // CSV 저장 오류 시 프로그램 종료
}
logger.Info("Processing complete", zap.String("outputFile", OUTPUT_CSV_FILE)) // 처리 완료 로그
fmt.Printf("Processing complete. Results saved to %s\n", OUTPUT_CSV_FILE) // 처리 완료 메시지 출력
}
간단한 백엔드를 만들일이 있어서 고민을 하다가, 유튜브 알고리즘에 뜬 아래 두 동영상을 보고 Golang Backend를 공부해야겠다고 다짐했습니다. 약 4년전, 공군 개발병 복무 시절, Golang + go gin 으로 간단한 REST API를 사지방에서 만들어보고 초당 몇번의 요청이 가능한지 테스트해보고 빨라서 놀랐던 기억이 있었는데, 그 시절이 떠오르네요. [Golang 도입, 그리고 4년 간의 기록 / Golang과 함께 서버 레이턴시를 500배 개선한 후기] https://www.youtube.com/watch?v=75X_eBW0mog
간단한 백엔드 개발을 위한 언어를 선택하는 과정에서 가장 중요하게 생각한 것은 성능이 빠른지와 단순한지였습니다. Golang은 다음과 같은 매력적인 장점들이 있습니다.
빠른 컴파일 속도 Golang의 빠른 컴파일 속도는 개발 생산성을 크게 향상시킵니다. 공군 시절 Spring 프로젝트를 수정하고 컴파일 하는데 1분 가까이 걸려서 멍때렸던 기억이 있었는데, 아직 경험해보지 못했지만 go는 프로젝트가 커져도 빠른 컴파일이 된다고 합니다. 뛰어난 동시성 처리 Go routine과 채널을 통한 동시성 제어는 Golang의 큰 장점 중 하나입니다. 요즘 Sass(Software as a service)가 많아지면서 Third party app(GPT etc..)과 API 연동할 일이 많은데 이때 강점을 가집니다. 언어의 단순성 간결하고 읽기 쉬운 문법으로 빠르게 학습할 수 있습니다. 사실 다른 빠른 언어들도 있지만, 개인적으로 go 언어가 이해가 잘되었습니다. 성능 최적화 메모리와 CPU 사용을 쉽게 최적화할 수 있다고 합니다. 고성능 애플리케이션 개발에 많이 사용된다고 합니다.
물론, Golang에도 몇 가지 단점이 있습니다..
에러 처리의 복잡성 모든 에러를 명시적으로 처리해야 해서 코드가 길어질 수 있습니다. GC 관련 이슈 대규모 시스템에서는 가비지 컬렉션으로 인한 성능 저하가 발생할 수 있습니다. 제네릭 지원 부족 제네릭 기능의 부재로 인해 코드 재사용성이 떨어질 수 있습니다. 특정 패턴 강제 에러 처리 등에서 특정 패턴을 따라야 하는 경우가 많습니다.
3. 선택한 기술 스택
Golang 커뮤니티를 탐색하면서 많은 개발자들이 추천하거나 github star가 많은 라이브러리를 찾았습니다. 제가 선택한 기술 스택은 다음과 같습니다:
Go Gin 경량화되고 빠른 웹 프레임워크로, RESTful API 개발에 적합합니다. SQLC SQL 쿼리를 Go 코드로 변환해주는 도구로, 타입 안정성과 성능을 모두 잡을 수 있습니다. PostgreSQL with RDS 요즘 많이 쓰는 관계형 데이터베이스입니다. Docker 개발 환경의 일관성을 유지할 수 있습니다. Github Action CI/CD easy..!
4. 특이했던 점
NestJS에서 사용했었던 schema.prisma처럼 migration 폴더에 데이터베이스 정보(PK, FK, Constraint, relation, type 등)를 기술하는 것. @Controller, @Service 같은 어노테이션이 없는것. pointer star (*), & 등 C 같은 느낌. 특이한 for문 등. 내일은 AWS RDS 데이터베이스 만들고, 연결해봐야겠다. 그리고 메모장같은 간단한 CRUD를 만들어보고 GPT나 Claude API 연동 시도해봐야겠다..!
안녕하세요, 여러분! 👋 오늘은 제가 트위터를 구경하다 우연히 발견한 신기하고 유용한 정보를 여러분과 공유하려고 해요. 2024년에 인기있는 60가지 AI 도구들이에요! 🚀💼 저도 지금 하나씩 사용해보고 있는 중인데, 몰랐던 도구들이 진짜 많기도하고 신기해서 여러분께 꼭 알려드리고 싶었어요! (제가 사용해본 것 형광펜 표시해볼게요)
1. 아이디어 발상 도구들 💡
Claude, ChatGPT, Gemini, Bing Chat, Perplexity 같은 AI 챗봇들이 아이디어 뱅크 역할을 해줘요! 상상력의 한계를 넓혀보세요!
2. 웹사이트 제작 도구들 🌐
@wegic_ai, Unicorn, 10Web, Framer, Dora로 멋진 웹사이트를 뚝딱 만들 수 있어요. 코딩 실력이 없어도 괜찮아요!
요즘 이 도구들을 하나씩 사용해보면서 매일 새로운 인사이트를 발견하고 있어요. ("AI로 이런 기능도 만들 수 있구나!, 어떻게 개발했지..?") 여러분도 한번 도전해보세요! 처음엔 어색할 수 있지만, 조금씩 익숙해지다 보면 어느새 AI 마법사가 되어 있을 거예요. 😉🧙♂️
코딩 입문 때부터 계속 쓰던 VS Code에서 벗어나기가 두려웠지만, 한 번 사용해보자는 실험 정신도 있었고 열정적인 추천에 솔깃해서 바로 구독하고 설치해봤는요. 일하다 말고 툴을 바꾸는 게 좀 도전적이라고 생각했지만.. 근데 VS code의 기능과 UI/UX가 매우 비슷해서 이질감을 못느꼈어요. 코드 생성형 AI 모델 선택도 가능하더라고요. Claude-3.5도 지원이 되어서 최근에 핫한 이 모델을 선택해서 쓰고 있어요.
3. 좋았던 점
명령어 생성 및 터미널 디버깅
기존에는 에러가 발생하면 터미널 내용을 복사해서 구글에 검색하곤 했는데, [Option + D] 단축키를 통해 터미널을 디버깅하고 설명해주는 게 편했어요.
터미널에 커서를 옮기고 [Command + K]를 누르면 아래 채팅이 뜨고 원하는 명령어를 입력하고 Enter를 누르면 터미널에 명령어가 작성됨.
변경하고 싶은 코드 부분을 드래고하고 [Command + L]를 누르면, 채팅 사이드바가 뜬다(코드가 입력됨).
코드가 결과로 나오고, 상단의 [Apply] 클릭하면 수정될 부분 보여주고, [Accept]/[Reject]를 선택할 수 있다.
4. 마무리
VS Code와 GitHub Copilot도 아직도 사람들이 많이 사용하는 유용한 툴이지만, Cursor IDE와 Claude 3.5 Sonnet 조합은 꽤 신선한 같아요. 앞으로 계속 사용할 것 같네요. 여러분도 한번 시도해보는 건 어떨까요?(+구독료는 덤) 새로운 경험에 푹 빠질지도 몰라요! 😉
Claude...! 너란 녀석
여러분은 어떤 도구를 쓰고 있나요? 각 도구의 좋았던 경험을 공유해주시면 정말 좋을 것 같아요! 자, 이제 저는 Cursor와 함께 코딩 여정을 시작하러 가볼게요. 다들 즐거운 코딩하세요! 읽어주셔서 감사합니다! 👋
아래 명령어에 파일명(./docker.sh)을 넣고 실행하면, 원격 레포지토리에 push 하면 해당 파일에 대한 기록이 모두 사라진다..! 실수로 중요한 정보를 원격 레포지토리에 올린 경우 유용하게 사용할 수 있을 것 같다. 그리고 .gitignore을 통해 원격 레포지토리에 올라가지 않도록 잘관리하자!
안녕하세요 여러분! 오늘은 제가 NestJS 백엔드 배포 중 겪었던 문제와 그 해결 과정에 대해 이야기하려 합니다. 아마 여러분 중에서도 Prisma Migrate를 사용하면서 문제에 부딪히신 분들이 계실 것 같아, 제 경험을 공유하고자 합니다.
1. 배경 및 문제점
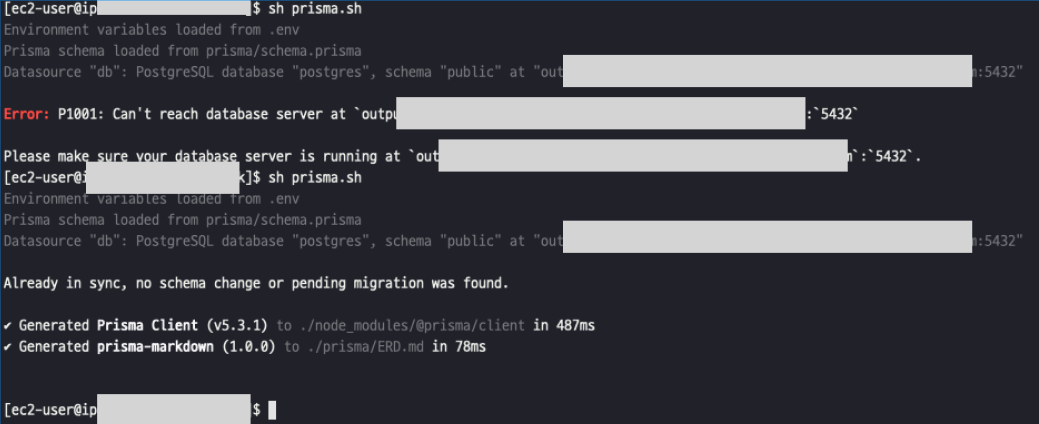
NestJS 프로젝트를 개발 중, Prisma를 사용하여 데이터베이스 관리를 하고 있었습니다. 개발을 마무리하고 AWS에 배포하는 과정에서 Prisma Migrate를 실행했으나 예상치 못한 오류가 발생했습니다.
npx prisma migrate dev --name init --schema=./prisma/schema.prisma
Error: P1001: Can't reach database server at `ouxxxxxxxxxxxxxxx.ap-northeast-2.rds.amazonaws.com`:`5432`
간단히 말하면, 이 명령어는 ./prisma/schema.prisma 파일에 정의된 데이터베이스 스키마 변경사항을 "init"이라는 이름의 마이그레이션으로 생성하고, 개발 환경의 데이터베이스에 적용하는 작업을 수행하는데
RDS(데이터베이스)에서 EC2에 대한 접근 규칙 (인바운드 규칙)이 허용되지 않아 접근할 수 없는 문제가 발생했습니다.
그러나 로컬 환경에서는 잘 작동하였기 때문에, AWS EC2, RDS 설정에 문제가 있을 것이라 판단했습니다. 퍼블릭 IPv4 주소, 프라이빗 IPv4 주소 또는 프라이빗 IP DNS 이름(IPv4만 해당) 중 무엇을 써서 인바운드 규칙에 추가할 지 고민하고 있었습니다.
3. VPC의 개념 탐구
문제의 원인을 찾아보던 중, AWS의 VPC(Virtual Private Cloud)를 활용하면 더 개념에 대해 깊게 알게 되었습니다. 간단히 말하면, VPC는 AWS에서 제공하는 가상 네트워크 환경입니다. 이 VPC 내에서 EC2, RDS 등의 리소스를 운영하면 보안 및 관리가 편리합니다.
EC2에서 RDS에 접근할 때 퍼블릭 IP를 사용하는 방식과 VPC를 활용하는 방식은 각각 다른 장단점을 가지고 있습니다. 이 두 방식의 장단점과 추천하는 접근 방법을 아래에 정리하였습니다.
3.1. 퍼블릭 IP를 통한 접근:
장점
간단한 설정: 외부에서 바로 접근할 수 있으므로 초기 설정이 간단합니다. 다양한 위치에서의 접근 가능: 어디에서든 인터넷이 연결되면 접근이 가능합니다.
단점:
보안 위험: 퍼블릭 IP는 인터넷상에서 어디서든 접근이 가능하므로, 보안 그룹 설정, 네트워크 ACL, 방화벽 등의 추가적인 보안 조치가 필요합니다.
비용: 트래픽 비용이 발생할 수 있습니다. AWS 내부에서의 데이터 전송은 보통 무료이나, 퍼블릭 IP를 통한 데이터 전송은 비용이 발생합니다.
변동성: EC2 인스턴스가 재시작될 때마다 퍼블릭 IP가 변경될 수 있습니다. (Elastic IP를 사용하지 않는 한)
3.2. VPC를 통한 접근:
장점: 보안: VPC 내에서의 통신은 private IP를 통해 이루어지므로 외부에서의 불필요한 접근을 차단할 수 있습니다.
성능: AWS 내부 네트워크를 통한 통신이므로 일반적으로 더 빠른 속도와 낮은 지연 시간을 가집니다.
비용 절감: VPC 내부에서의 데이터 전송은 일반적으로 비용이 발생하지 않습니다.
고정된 IP: VPC 내에서는 private IP가 변경되지 않습니다.
단점: 설정 복잡성: VPC, 서브넷, 라우팅 테이블, 보안 그룹 등 여러 AWS 서비스의 설정이 필요합니다.
3.3. 추천 방법 및 이유:
VPC를 통한 접근을 추천합니다. 주요 이유는 다음과 같습니다:
보안: 데이터베이스는 중요한 정보를 저장하므로 최상의 보안이 필요합니다. VPC를 사용하면 외부의 불필요한 접근을 제한할 수 있습니다.
성능 및 비용: AWS 내부 통신은 빠르며 대부분의 경우 추가 비용이 발생하지 않습니다.
유연성: VPC를 사용하면 보안 그룹, 네트워크 ACL 등을 통해 네트워크 트래픽을 세밀하게 제어할 수 있습니다.
결론적으로, 보안과 비용, 성능 측면에서 VPC 내에서의 접근 방식이 더 우수하다고 판단됩니다.
4. 해결 과정
VPC 설정 확인:
먼저, EC2와 RDS가 동일한 VPC 내에 있는지 확인했습니다. 동일한 VPC 내에 있었기 때문에 내부 IP로 통신이 가능하다는 것을 알게 되었습니다.
보안 그룹 설정:
EC2와 RDS 간의 통신을 허용하기 위해, 보안 그룹에서 해당 IP와 포트(Prisma의 경우 기본적으로 5432)를 열어주었습니다.
Prisma 설정 변경:
마지막으로, Prisma 설정에서 데이터베이스의 연결 주소를 RDS의 private IP로 변경해주었습니다.
5. 결과
위의 변경 후, 다시 Prisma Migrate를 실행하니 이전에 발생했던 문제 없이 성공적으로 마이그레이션을 완료할 수 있었습니다.
An error occurred (ApplicationDoesNotExistException) when calling the CreateDeployment operation: Applications not found for ***
Error: Process completed with exit code 254.
GitHub action, EC2, S3, CodeDeploy 모든 권한을 설정했음에도 codedeploy 애플리케이션을 찾을 수 없다는 위의 오류가 계속 나타났습니다. 원인을 찾던 중, EC2 지역이 ap-southeast-2 (Sydney)로 잘못 설정된 것을 발견했습니다.
2. 해결 방법: AMI(EC2의 복제본) 이미지 생성 및 이동
AWS EC2에서 특정 인스턴스의 지역을 직접 변경할 수는 없습니다. 대신 EC2의 복제본인 AMI을 생성하여 이를 다른 지역으로 옮겨 실행해야 합니다.
이미지 생성
첫 번째 단계는 기존 시드니에서 실행되는 EC2 서버를 그대로 이미지화하는 것입니다.
인스턴스를 오른쪽 클릭한 후 [이미지] - [이미지 생성]을 클릭하여 이미지를 생성하십시오.
약 10분 후 [AMI] 탭으로 이동하면 이미지가 성공적으로 생성된 것을 볼 수 있습니다. 그러나 이런 방식으로 생성된 이미지도 지역별로 저장됩니다. [시드니]에서 AMI로 생성되었다는 메시지가 뜨지만 놀라지 않아도 됩니다. AMI는 데이터이므로 다른 지역(서울)로 복사할 수 있습니다.
AMI(Amazon Machine Image) 복사
오른쪽 클릭하여 [AMI 복사] 버튼을 누르십시오. 이후 서울 지역으로 AMI를 복사할 수 있습니다.
새 EC2 인스턴스 생성
복사된 이미지로 새 EC2 인스턴스 생성을 해보도록 하겠습니다
이제 이렇게 생성된 이미지를 사용하여 서울 지역에 인스턴스를 생성하겠습니다. 복사된 이미지로 인스턴스를 생성하면 기존 서버를 그대로 복사하여 사용할 수 있으므로 서버를 재배치하는 것과 거의 동일합니다.
남은 데이터 삭제
서버 이전이 완료되면 기존 지역(시드니)의 인스턴스와 AMI(시드니 지역) 같은 모든 데이터를 삭제하고 정리해야 합니다. 사용하지 않는 서버를 계속 가지고 있으면 불필요한 요금이 발생할 수 있습니다.
먼저 인스턴스를 [종료]하여 삭제하십시오. 그런 다음 [AMI] 탭에서 이미지 파일을 삭제하십시오. 그런 다음 모든 스냅샷과 기타 데이터를 제거할 수 있습니다. 결과적으로 완전히 지울 수 있습니다.
이 포스트를 통해 AWS EC2 인스턴스를 다른 지역으로 이동하는 방법을 알게 되셨길 바랍니다. 문제가 발생할 때 포기하지 말고 해결책을 찾는 것이 중요합니다.
재부팅 시에도 스왑 메모리가 활성화되도록 /etc/fstab 파일에 다음 줄을 추가합니다.
/swapfile swap swap defaults 0 0
이렇게 설정 후, free -h 명령어로 스왑 메모리가 제대로 활성화되었는지 확인할 수 있습니다.
4. 마치며
메모리 부족 문제는 성능 최적화, 적절한 자원 할당, 코드 최적화 등 다양한 방법으로 해결할 수 있습니다. 여기서 제시한 방법은 임시적인 해결책 중 하나일 뿐, 장기적으로는 어플리케이션의 메모리 사용 패턴을 분석하고, 필요한 최적화 작업을 통해 근본적인 해결을 추구해야 합니다.
먼저, 필요한 도메인을 가비아에서 구매해줍니다. 원하는 도메인 이름을 검색 후 사용 가능하면 구매를 진행합니다.
2. AWS EC2에서 NestJS 서비스 구동
본인의 AWS 계정에서 EC2 인스턴스를 생성 후, NestJS 서비스를 배포 및 구동시킵니다. 이때, EC2 인스턴스의 고정 IP(Elastic IP)를 할당받아 기록해둡니다.
3. AWS Route 53 설정
AWS Management Console에 로그인 후 Route 53 서비스로 이동합니다. Hosted zones에서 새로운 Hosted Zone을 생성합니다. 여기에 가비아에서 구매한 도메인 이름을 입력합니다. 생성된 Hosted Zone 내에 A 레코드를 추가합니다. 값은 EC2의 Elastic IP로 설정합니다. 이후, Route 53에서 제공하는 네임서버(NS) 레코드들을 확인합니다.
4. 가비아에서 네임서버 설정 변경
가비아 웹사이트에서 로그인 후 내 도메인 관리 페이지로 이동합니다. 도메인의 네임서버 설정을 변경하는 옵션으로 들어갑니다. AWS Route 53에서 제공받은 네임서버(NS) 레코드들로 변경해줍니다.
5. SSL 인증서 적용
CSR 생성: 원하시는 방법으로 CSR을 생성합니다. CSR이 없다면 신규로 생성해야 합니다. 인증 방식 선택: 웹인증(HTTP) 또는 DNS 레코드 인증을 선택하여 진행합니다. 도메인 명 설정: www 포함 여부에 따라 선택합니다. 발급받은 인증서와 개인 키는 EC2 인스턴스 안에 안전하게 보관합니다.
이상으로 AWS EC2, Route 53, 그리고 가비아 도메인을 활용하여 NestJS 서비스에 SSL 인증서를 적용하는 방법을 소개했습니다. 문제가 발생하거나 추가적인 궁금증이 생기면 언제든 댓글로 질문해주세요!
안녕하세요! 이번 포스트에서는 ShoppingMall 서비스의 Prisma 데이터베이스 스키마를 다루며, 각 테이블 간의 관계와 그에 따른 중요한 제약조건을 살펴볼 예정입니다. 데이터베이스의 설계는 서비스의 핵심적인 기능과 성능에 큰 영향을 미치므로, 잘 이해하고 설계하는 것이 중요합니다.
1. 주요 테이블 및 관계
1.1. User
User 테이블은 서비스의 사용자에 관한 정보를 담당합니다. 각 사용자는 여러 주문을 가질 수 있으며, 일부 사용자는 가게(Store) 정보와 일대일 관계를 형성합니다.
model User {
id Int @id @default(autoincrement())
storeId Int? @unique
...
Store Store?
ordersAsSeller Order[]
ordersAsBuyer Order[]
...
}
1.2. Store
Store 테이블은 개별 가게 정보를 담당합니다. 가게는 한 명의 사용자에게 속하며, 여러 상품(Product)을 소유할 수 있습니다.
model Store {
id Int @id @default(autoincrement())
userId Int @unique
...
user User @relation(fields: [userId], references: [id])
product Product[]
...
}
1.3. Product
Product 테이블은 상품에 관한 정보를 담당합니다. 각 상품은 한 개의 가게에 속하며, 여러 주문(Order)에 연결될 수 있습니다.
model Product {
id Int @id @default(autoincrement())
storeId Int
...
store Store @relation(fields: [storeId], references: [id])
Order Order[]
...
}
1.4. Order
Order 테이블은 주문 정보를 관리합니다. 주문은 한 명의 판매자와 한 명의 구매자, 그리고 한 개의 상품과 다대다 관계를 형성합니다.
model Order {
id Int @id @default(autoincrement())
userSellerId Int
userBuyerId Int
productId Int?
...
seller User @relation("OrderToSeller", fields: [userSellerId], references: [id])
buyer User @relation("OrderToBuyer", fields: [userBuyerId], references: [id])
product Product? @relation(fields: [productId], references: [id])
...
}
2. 데이터베이스 관계와 그 의미
2.1. 일대일 관계 (1:1)
User와 Store 사이의 관계는 일대일입니다. 한 사용자는 하나의 가게만을 소유할 수 있으며, 그 반대도 성립합니다.
2.2. 일대다 관계 (1:N)
Store와 Product 사이에는 일대다 관계가 있습니다. 한 가게는 여러 상품을 소유할 수 있지만, 각 상품은 하나의 가게에만 속합니다.
2.3. 다대다 관계 (N:N)
User와 Order 사이에는 다대다 관계가 있습니다. 여기서 사용자는 여러 주문을 할 수 있으며, 각 주문은 한 명의 판매자와 한 명의 구매자를 갖게 됩니다.
3. User와 Order의 다대다 관계 이해하기
우선, 기본적으로 한 사용자는 여러 주문을 생성할 수 있습니다. 예를 들면, 온라인 쇼핑몰에서 쇼핑을 할 때마다 새로운 주문이 생성되는 것과 같습니다. 따라서 User와 Order 사이에는 일대다 관계가 성립합니다.
그렇다면 왜 다대다 관계라고 표현했을까요? Order의 관점에서 보면, 하나의 주문은 한 명의 구매자와 한 명의 판매자를 갖습니다. 즉, 두 명의 사용자가 관련되어 있습니다. 이를 표현하기 위해 Order는 두 개의 사용자 ID를 참조합니다: userBuyerId와 userSellerId. 이 두 관계 모두 일대다 관계이지만, 각각의 관계가 Order를 중심으로 User 테이블을 두 번 참조하므로, 전반적으로 다대다의 관계 특성을 갖게 됩니다.
3.1. 예시로 이해하기
User A는 판매자로서 여러 상품을 판매하고 있습니다.
User B는 A의 상품 중 하나를 구매하려고 주문을 생성합니다.
이 주문은 A를 판매자로, B를 구매자로 갖게 됩니다.
Order 테이블에 새로운 레코드가 생성되며, userSellerId는 A의 ID를, userBuyerId는 B의 ID를 참조하게 됩니다.
User와 Order 사이의 관계는 사용자의 역할(구매자 또는 판매자)에 따라 일대다 관계가 두 번 성립하므로, 전체적으로는 다대다 관계의 특성을 갖습니다. 이러한 복잡한 관계는 데이터베이스 설계 시 정확한 이해와 적절한 구조로 표현해야 합니다.
4. 다대다 관계 이해하기 (학생과 수업의 관계)
다대다 관계는 많은 데이터베이스 설계 상황에서 흔히 나타납니다. 학교나 대학교의 수업과 학생 관계를 예로 들어보겠습니다.
4.1. 시나리오
대학교에서 학생들은 여러 수업을 수강할 수 있습니다. 반대로 한 수업은 여러 학생들에게 강의될 수 있습니다.
학생 테이블 (Student): 각 학생은 고유의 학번, 이름 등의 정보를 가집니다.
수업 테이블 (Class): 각 수업은 고유의 코드, 수업 이름, 강사 정보 등을 가집니다.
이렇게 단순하게 두 테이블로 구성된다면 학생과 수업 사이는 다대다 관계를 형성합니다. 학생 A는 수업 X, Y, Z를 수강할 수 있고, 수업 X는 학생 A, B, C에게 강의될 수 있기 때문입니다.
다대다 관계를 표현하는 방법
대부분의 RDBMS는 다대다 관계를 직접 표현할 수 없기 때문에, 중간에 연결 테이블 (junction table 또는 bridge table)이 필요합니다.
4.2. 수강 테이블 (Enrollment, 학생과 수업 연결)
학생과 수업의 관계를 나타내기 위한 테이블입니다. 이 테이블에는 studentId와 classId라는 두 개의 외래 키가 포함됩니다. 각 레코드는 특정 학생이 특정 수업을 수강한다는 것을 나타냅니다. 이렇게 Enrollment 테이블을 통해 학생과 수업 사이의 다대다 관계가 명확하게 표현됩니다.
4.3. 결론
다대다 관계는 두 엔터티 간에 양방향의 1:N 관계가 성립할 때 발생합니다. 이 관계를 RDBMS에서 효율적으로 표현하려면 연결 테이블이 필요합니다. 이 연결 테이블은 두 엔터티 간의 연관성을 저장하며, 실제 응용 프로그램에서는 다양한 쿼리나 조인 연산을 통해 데이터를 검색하게 됩니다.
5. 테이블의 주요 제약조건
5.1. Unique 제약조건
User 테이블의 email과 phoneNumber는 서비스 내에서 중복될 수 없으므로 @unique 제약조건이 설정되어 있습니다. 이는 사용자의 고유한 식별 정보로 사용되기 때문입니다.
5.2. Optional vs Required
Prisma 스키마에서 ?는 해당 필드가 선택적(optional)임을 나타냅니다. 예를 들어, User의 storeId는 ?가 붙어있어, 모든 사용자가 가게 정보를 갖지 않아도 됩니다.
6. 종합 및 제약 조건의 중요성
데이터베이스의 관계 설정은 데이터의 일관성과 무결성을 유지하기 위한 핵심 요소입니다. 잘못된 관계나 제약 조건 설정은 추후 데이터 충돌이나 중복 등의 문제를 일으킬 수 있습니다.
Docker를 사용하여 애플리케이션을 컨테이너화하면서 exec format error라는 오류에 직면한 적이 있나요? 이 오류는 스크립트나 바이너리 파일의 형식이 컨테이너 내에서 실행되기에 적합하지 않을 때 발생합니다. 여기에서는 이 문제의 원인과 해결 방법에 대해 간략하게 알아보겠습니다.
문제 상황
Dockerfile 내에서 다음과 같은 명령어를 사용하여 AWS 자격 증명을 설정하는 스크립트를 실행하려고 했습니다:
서버 배포에 Dockerfile을 사용하고 있기 때문에, Dockerfile도 아래와 같이 설정하여 자격 증명을 설정하도록 했습니다.
# 기본 이미지 설정
FROM node:14
# 작업 디렉토리 설정
WORKDIR /app
# 필요한 파일들을 복사합니다
COPY .env .env
COPY set_aws_credentials.sh set_aws_credentials.sh
# AWS credentials 설정
RUN chmod +x set_aws_credentials.sh && ./set_aws_credentials.sh
# 나머지 설정...
그런데 docker 환경은 제 M1 맥미니 환경과 달라서 이 과정에서 다음과 같은 오류가 발생했습니다
NestJS + Prisma :: 예외를 두려워 마라! NestJS AllExceptionFilter의 활용 전략, 공통 응답 구조, Exception 생성해서 사용하기
서론
현대 응용 프로그램에서는 사용자에게 관련성 있는 명확한 에러 메시지를 전달하기 위해 구조화된 에러 처리가 중요한 역할을 합니다. NestJS와 Prisma 같은 프레임워크를 사용하면 이를 원활하게 효율적으로 구현할 수 있습니다. 사용자 정의 예외, 응답 DTO, 그리고 NestJS와 Prisma의 강력한 기능을 어떻게 활용하는지 자세히 알아봅시다.
1. ExceptionCode 구조
사용자 정의 예외에 들어가기 전에 우리의 에러 코드에 대한 구조화된 형식을 만드는 것이 중요합니다. 코드에서 제공하는 내용은 다음과 같습니다:
NestJS의 AllExceptionFilter를 사용하면 애플리케이션에서 던진 모든 에러, 사용자 정의 예외를 포함하여 포착할 수 있습니다. 이는 일관된 에러 응답 구조를 보장하고, 중복 코드를 줄이며, 에러 처리 메커니즘을 강화합니다.
AllExceptionFilter를 활용하면 NestJS 애플리케이션 내에서 발생하는 모든 예외를 효과적으로 포착하고 관리할 수 있다. 이를 통해 사용자에게 일관된 에러 응답을 제공하며, 개발자는 디버깅을 쉽게 할 수 있다. 모든 애플리케이션에서 이러한 중앙 집중식의 에러 처리 방식을 도입하는 것은 좋은 방법이다.
이 AllExceptionFilter에서는 여러 가지 예외 유형, 예를 들면 사용자 정의 예외, HTTP 예외, Prisma 에러 등을 분기처리하여 각각의 상황에 맞는 응답을 반환한다.
BaseException: 사용자 정의 예외로서, 해당 예외에 할당된 상태 코드, 내부 코드 및 메시지를 반환한다.
HttpException: NestJS에서 제공하는 기본 HTTP 예외. 상태 코드와 응답 내용을 반환한다.
PrismaClientKnownRequestError & PrismaClientUnknownRequestError: Prisma ORM에서 발생하는 알려진 및 알려지지 않은 에러. 각각에 맞는 코드와 메시지를 반환한다.
Error: 기타 일반적인 JavaScript 에러. 기본적인 정보를 반환한다.
import {
ExceptionFilter,
Catch,
ArgumentsHost,
HttpException,
} from '@nestjs/common';
import { BaseException } from './base_exception';
import {
PrismaClientKnownRequestError,
PrismaClientUnknownRequestError,
} from '@prisma/client/runtime/library';
import { ExceptionCodeEnum } from 'src/exception/exception_code_enum';
/*
@Catch(HttpException)은
http 통신의 예외를 캐치하겠다는 뜻입니다.
만약 모든 예외를 캐치하고 싶다면
@Catch()로 적용하시면 됩니다.
*/
@Catch()
export class AllExceptionFilter implements ExceptionFilter {
async catch(
exception: BaseException | HttpException | Error,
host: ArgumentsHost,
) {
const ctx = host.switchToHttp();
const response = ctx.getResponse();
// const request = ctx.getRequest();
let status: number = ExceptionCodeEnum.Unknown.status;
let code: string = ExceptionCodeEnum.Unknown.code;
let message: string = ExceptionCodeEnum.Unknown.message;
if (exception instanceof BaseException) {
status = exception.getStatus();
code = exception.code;
message = exception.message;
} else if (exception instanceof HttpException) {
status = exception.getStatus();
code = exception.getStatus().toString();
message = exception.getResponse().toString();
} else if (exception instanceof PrismaClientKnownRequestError) {
status = ExceptionCodeEnum.PrismaClientKnownRequestError.status;
code = exception.code;
message = exception.message;
} else if (exception instanceof PrismaClientUnknownRequestError) {
status = ExceptionCodeEnum.PrismaClientUnknownRequestError.status;
code = ExceptionCodeEnum.PrismaClientUnknownRequestError.code;
message = ExceptionCodeEnum.PrismaClientUnknownRequestError.message;
} else if (exception instanceof Error) {
status = ExceptionCodeEnum.Unknown.status;
code = exception.name;
message = exception.message;
}
response.status(status).json({
code: code,
message: message,
data: null,
});
}
}
7. NestJS와 Prisma의 장점:
NestJS: 데코레이터, 가드, 인터셉터를 제공하는 다양한 프레임워크로 개발이 간편하고 유지 관리가 쉽습니다. Prisma: 차세대 ORM으로, 타입 안전한 데이터베이스 쿼리를 제공하여 런타임 에러를 줄이고 개발자의 생산성을 향상시킵니다. 두 도구를 결합하면, 강력하고 유지 관리가 쉽며 효율적인 애플리케이션 구조를 만들 수 있습니다.
8. 결론
위에 제시된 도구와 방법론을 사용함으로써 효과적인 에러 처리는 더 이상 어려운 작업이 아닙니다. 사용자 정의 예외, 통일된 응답 DTO, 그리고 NestJS와 Prisma의 힘을 활용하여 개발자는 유연하고 사용자 친화적인 응용 프로그램을 만들 수 있습니다.